Pożytki praktyczne z egzaminu CFPS (Certified Function Point Specialist)
Przystępując do jakiegoś egzaminu z inżynierii oprogramowania często zmuszanie jesteśmy do opanowywania wiedzy, co do której nie jesteśmy pewni, czy kiedykolwiek wykorzystamy ją w praktyce. Oczywiście zdobycie certyfikatu z analizy biznesowej, zarządzania projektami czy testowania oprogramowania nobilituje nas zawodowo, a dla wielu proces zdawanie przebiega według schematu „zakuj, zdaj, zapomnij”. Zazwyczaj bowiem widza teoretyczna wyniesiona z przygotowywania się do egzaminu porządkuję świat pojęć, daje możliwość lepszego operowanie różnego rodzaju technikami, ale niektóre szczegółowe pojęcia, które trzeba znać aby nasza przygoda z egzaminem miała pozytywny finał to spora przesada. Oczywiście dobrze wiedzieć, że „wykres spalania” nie oznacza diagramu pokazującego wypalanie zawodowe pracownikow w branży IT ani nie odzwierciedla pracę silników czterosuwowych, a „wyrocznia testowa” to nie jest taka pani, co wróży z fusów i na tej podstawie potrafi pokazać w której części oprogramowania są błędy, ale ile razy w życiu tester będzie robił „analizę mutacji”? Kto nie wie, co to jest „analiza mutacji” odsyłam do „Słownika wyrażeń związanych z testowaniem” opublikowanym na stronie SJSI.
Zdanie egzaminu CFPS jest znacznie trudniejsze niż przykładowo egzaminów z rodziny ISTQB. Teorii jest o niebo więcej, a kryteria zdawalności zliczenia znacznie wyższe. Sam egzamin CFPS składa się trzech części: 50 pytań teoretycznych, 50 zadań obliczeniowych i 10 dość rozbudowanych Case Study (patrz wpis: Nadchodzą zmiany sposobu zdawania iegzaminu IFPUG CFPS Certified Function Point Specialist). Mamy na odpowiedź 3 godziny. Hardkore.
Jednak w przypadku CFPS widzę głęboki sens opanowania dziesiątków definicji. Dlaczego? Zaraz napiszę.
Pamiętacie może film „Dejavu” Julisza Machulskiego. Wstępuje tam grupa muzyków, która w okresie NEPu w Sowieckiej Rosji próbuje grać jazz. Ponieważ jednak ZSRR odgrodził się od reszty świata „żelazną kurtyną” (zanim wymyślił ten termin Winston Charchile), młodzi jazzmani nie mając innych sposobów sprawdzenia, czy rzeczywiście dżezują, grają przybyszom z zagranicy, szczególnie obywatelom amerykańskim kilka taktów swoich improwizacji i pytają z nadzieją w głosie”
„Czy to jest synkopa?”
Ja często mam Dejavu filmu „Dejavu” na szkoleniach dotyczących analizy punktów funkcyjnych IFPUG. W połowie szkolenia Kursanci wyciągają dokumenty wymagań, jakieś swoje stare wyceny czy wręcz pokazują mi swoje aplikacji i pytają:
„Czy to jest Punkt Funkcyjny?”
„Czy mam to „coś” liczyć, czy nie? A jeżeli mam liczyć tego „cosia”, to jako co? Jako ILF, EIF, EQ, EO, EI, a może jako DET, RET czy też FTR?
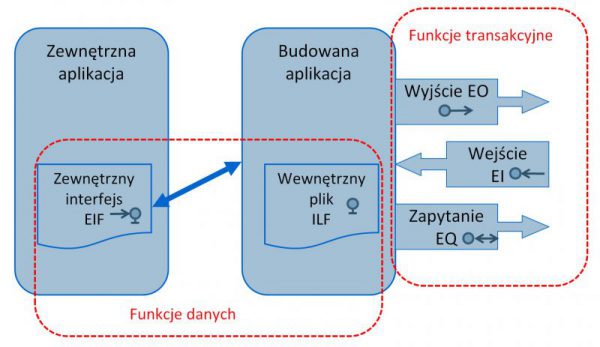
W takich chwilach podręcznik „Function Point Counting Practices Manual” nigdy mnie jeszcze nie zawiódł. Zawsze znajdzie się jakaś definicja, która pozwoli dokonać prawidłowej analizy i pomóc w określeniu jak „to coś”, co pokazują uczestnicy policzyć. Dam przykład.
Zliczmy punkty funkcyjne dla system, za pomocą którego studenci mogą rejestrować się na zajęcia. Po wyborze funkcji „rejestracja na kurs” otwiera się poniższa formatka.
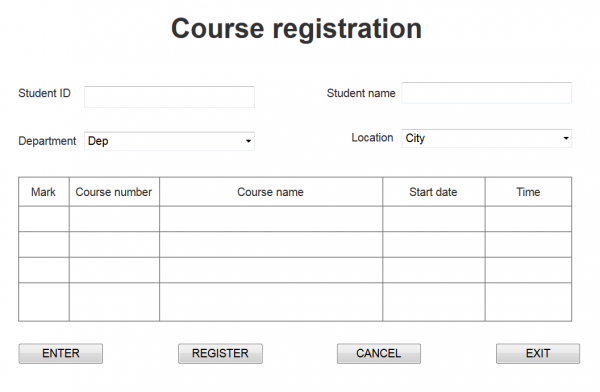
Student wpisuje w pole Student ID swój numer. Jeżeli osoba o takim identyfikatorze nie figuruje w pliku logicznym „Student” to na ekranie wyświetlany jest stosowny komunikat o błędzie i student może albo skorygować swój numer ID, albo naciskając przycisk CANCEL zrezygnować z rejestracji. Jeżeli zaś numer ID jest poprawny, z pliku „Student” jest odczytywane nazwisko studenta i jest ono wyświetlane na ekranie. Wtedy student może posługując się rozwijalną listą „Department” wybrać wydział, na którym prowadzone są interesujące go zajęcia. Dodatkowo z rozwijanej listy „Location” student wybiera jedno z czterech miast, w których może uczęszczać na kursy.
Po wybraniu wydziału i lokalizacji w tabeli wyświetlają się dostępne na danym wydziale i w danej lokalizacji kursy, na które może się student zarejestrować. Informacje o kursach przechowywane są w pliku „Kurs” należnym do innej aplikacji o nazwie „Uczelnia”. Rejestracja przebiega w ten sposób, że student wpisuje znacznik X w kolumnie „Mark” w tych wierszach, które odnoszą się do interesujących go kursów. Po naciśnięciu klawisza „ENTER” lub „REGISTER” system sprawdza, czy wybrany kurs jest dostępny i jeżeli tak, to student zostaje zapisany na kurs i zostaje wyświetlony komunikat potwierdzający., Jeżeli zaś kurs jest niedostępny, to pojawia się stosowny komunikat o błędzie i ekran jest odświeżany, a z tabeli „znika” niedostępny kurs.
Dokonując analizy punktów funkcyjnych dla aplikacji „Register” z łatwością stwierdzamy, że:
- Funkcja danych „Student” to ILF
- Funkcja danych „Kurs” to EIF (plik ten jest zarządzany prze inną aplikację, w tym wypadku przez „Uczelnia”
- Proces „Rejestracja na kurs” jest liczony jako funkcja transakcyjna EI
Jest jeszcze jedna zagadka do rozwiązania:
Czy liczymy rozwijane listy „Department” i „Location”, a jeżeli tak, to jak.
W toku dalszych analiz otrzymaliśmy z pozoru paradoksalną odpowiedź. Rozwijaną listę „Department” liczymy jako EQ, a rozwijaną listę „Location” nie liczymy jako osobny punkt funkcyjny.
Jak to możliwe? Przecież oba obiekty niczym nie różnią się od siebie – to rozwijane listy. Ale czy aby na pewno nie ma między nimi różnic?
Licząc punkty funkcyjne trzeba permanentnie uprawiać analitykę śledczą i starać się wyłuskać z wymagań maksymalną liczbę interesujących nas faktów. W tym wypadku kluczowym pytaniem było, skąd się wzięły listy wyświetlane w obiektach „Department” i „Location”. Jak się okazało, lista wydziałów importowana jest z pliku o nazwie „Department”, a którym zarządza aplikacja „Uczelnia”. Lista miast wyświetlana w polu „Location” jak wykazało śledztwo, zakodowana jest na sztywno w aplikacji, którą szacujemy.
W tym miejscu pojawia się kilka pytań, na które postaram się odpowiedzieć w oparciu o zapisy obecne w podręczniku IFPUG.
Naszą wiedzę o systemie informatycznym czerpiemy ze „zebranej dokumentacji” (Gathering documentation). Naszym zadaniem jest obliczyć w punktach funkcyjnych wielkości oprogramowania zbudowanego w oparciu o zgromadzoną dokumentację w skład której wchodzą przeważnie artefakty z modelu wymagań (Przypadki użycia, opisy procedur i funkcji, modela klas i obiektów, diagramy przepływu danych, projekty GUI, diagramy procesów biznesowych (BPMN, UML lub w innej notacji) itp. „Ale” – jest jedno „ale”. Wg podręcznika naszej analizie mogą także(i powinny jeżeli mamy do nich dostęp) podlegać „other software development artifacts”. Innymi słowy nie gardzimy takimi dokumentami, jak:
- Physical design models
- Operational models
- Program and module specifications
- Test cases
O.K. Zatem mamy w procesie analizy PF odwoływać się nie tylko do dokumentów z obszaru wymagań, ale tych z obszaru technicznego opisu rozwiązania. To teraz pytanie drugie, dlaczego jeżeli rozwijana lista na projekcie ekranu pochodzi z EIF lub ILF, to liczymy ją jako jedno EQ, a jeżeli pochodzi z tablicy zakodowanej w programie, to ją nie liczymy? Tutaj musimy sięgnąć po definicje encji biznesowych (Part 3 Chapter 1, „Types of Data Entities”).
Wyróżniono trzy rodzaje danych:
- Dane biznesowe (Business Data)
- Dane referencyjne (Reference Data)
- Dane kodowe (Code Data)
Dane biznesowe nazywane także obiektami biznesowymi (Business Objects) lub głównymi danymi użytkownika (Core User Data) stanowią znaczącą część wszystkich danych. Dane te są przechowywane przez systemy informatyczne i odczytywane w toku realizacji procesów biznesowych. Użytkownicy biznesowi zwykle potrafią świetnie ten typ danych zidentyfikować i można je znaleźć na przykład w modelu dziedziny (konceptualnym modelu klas). Dane te mają bardzo dynamiczną naturę i są w trakcie rutynowych działań biznesowych tworzone, modyfikowane i kasowane. Przykładami danych biznesowych mogą być pliki do przechowywania faktur, zamówień, informacji o kontrahentach i transakcjach, albo jak w naszych poprzednich rozważaniach, zbiór danych o studentach, dostępnych kursach czy też wykładowcach. Często dane biznesowe zawierają dużą liczbę atrybutów charakteryzujących obiekty biznesowe przez nie opisywane. Z punktu widzenia procesu zliczania PF wszystkie dane biznesowe musimy policzyć jak ILFy lub EIFy.
Drugim rodzajem danych wyróżnionym przez IFPUG są dane referencyjne. Służą one zazwyczaj do przechowywania reguł biznesowych niezbędnych by prawidłowo używać dane biznesowe. Przykładowo w systemie płacowym są dane określające stawki podatków i innych danin państwowych po to, aby system mógł obliczyć prawidłowo wynagrodzenie. Jak wykazują najnowsze badania, systemy tworzone dla niektórych sektorów (ubezpieczenia, handel detaliczny, służba zdrowia…) w modelu wymagań zawierają prawie tyle samo opisów tak zwanego modelu decyzyjnego (patrz artykuł Modelowanie decyzji za pomocą notacji DMN – część pierwsza) co opisu procesów biznesowych. Wszystkie te tabele upustów, skomplikowane tabele stawek ubezpieczeniowych czy też dane służące do określania marszruty dokumentów, to dane referencyjne.
W stosunku do danych biznesowych dane referencyjne mają mniejszą dynamika (jak często zmieniają się stawki podatkowe?), ale często dla uzyskania elastyczności aplikacji są zarządzane przez użytkowników biznesowych (prawdę mówiąc idea DMN polega na odebraniu programistom i pracownikom IT systemu podejmowania decyzji i oddanie go we władanie biznesowi). Mówiąc językiem IFPUG, większość funkcji transakcyjnych wymaga dostępu do danych referencyjnych. Dane referencyjna mają z definicji jeden rekord i zwykle na tym się kończy. Zazwyczaj dane referencyjne są liczone jako funkcje danych.
Ostatni typ danych to dane kodowe, które nazywane są „List Data” lub „Translation Data” z racji tego, że programiści stosują często tabele służące do przetłumaczenia abstrakcyjnych kodów na terminy lepiej rozpoznawalne dla użytkowników. Na przykład kod lotniska (Airport-Code) na nazwę lotniska (Airport-Name). Czasami oczywiści ma sens operacja odwrotnego kodowania ;-) Przykładowo piję w tej chwili kawę z kubka należącego do serii PANETONE Universe, a kubek jest w kolorze dyni (Pumpkin). No i pytanie o jaką dynię chodzi.
Czy taką?

A może taką?

Zapewne znajdą się tacy, którzy uznaję, że oba kolory są identyczne ;-)
Kubek wygląda zaś tak:

Na szczęście by uniknąć kłopotów z identyfikacją kolorów już dawno temu amerykańska firma Pantone Inc. opracowała kody do określania kolorystyki. Barwa dyniowata to kod 1505 i wszystko jasne!
Pamiętajmy jednak że według IFPUG dane kodowe to nie tylko zamienniki (substytuty) innych zmiennych (podajemy kod Pantone zamiast nazwy barwy, na przykład fuksji). Mamy trzy typy danych kodowych:
- Substitution Data
- Static or Constant Data
- Valid Values
Znaczenie zamienników już rozumiemy, czym zatem są stałe i dane walidacyjne?
Dane stałe dzielą się na:
- One Occurrence
- Static Data
- Default Values
One Occurrence to takie dane które mają jedną i tylko jedną instancję niezależnie od liczby atrybutów. Dobrym przykładem takich danych jest stopka redakcyjna (impressum), która zwiera informacje o nazwie firmy, adresie, telefonach i jest dodawana do różnych dokumentów generowanych przez system na przykład do formatu pdf. Dane tego typu mogą być zmieniane, ale zachodzi to bardzo rzadko. Zwykle są one zakodowane wewnątrz aplikacji.
Static Data to z kolei taki rodzaj danych stałych, które ze swej natury są statyczne. Przykładem takich danych może być lista miast, gdzie są filie naszej korporacji, albo tablica zawierająca trzy kolumny: symbol pierwiastka chemicznego, jego liczbę atomową i opis. Takimi danymi statycznymi mogą też być tabele służące nam do przeliczenia na Nieskoordynowane Punkty Funkcyjne zidentyfikowane przez nas PF w zależności od ich złożoności.
Wreszcie Default Values. Są to dane używane do zainicjowania wartości atrybutów nowych instancji obiektów biznesowych.
Został nam do omówienia ostatni typ danych – wartości walidacyjne (Valid Values). Jak łatwo się domyśleć są to dane wykorzystywane w celu zwiększenia przyjazności interfejsu aplikacji (user friendliness) oraz zmniejszeniu ilości błędnie wpisywanych danych. Gdy na przykład w polu „data” pojawia się kalendarz i tylko z niego możemy wyklinać datę w Polę, to zapobiegamy w ten sposób sytuacji, że ktoś „z palca” wpiszę datę 30 luty na przykład. Wartości walidacyjne służą do określania przedziałów danych poprawnych. Najwyższa i najniższa temperatura, najniższa i najwyższa wysokość czegoś i tak dalej.
Skoro już wiemy jak zidentyfikować dane kodowe, to najważniejszymi informacjami, które w tym temacie możemy znaleźć w podręczniku IFPUG, to:
- Nie zliczamy dane kodowe jako funkcje danych
- Nie zliczamy dane kodowe jako RETy i DETy
- W funkcjach transakcyjnych nie zliczamy odwołania do danych kodowych jako FTRy
- Przeglądanie danych kodowych nie może zostać policzone jako funkcja transakcyjna
Reasumując, rozwijaną listę „Location”nie mogę policzyć jako EQ, a przy szacunku złożoności funkcji rejestracji studenta na wykłady nie mogę ani dodać dodatkowy DET za „listę rozwijaną”, ani dodatkowy FTR za korzystanie z niej na formatce.